End-to-End Reliability Experimentation and Premortem Framework¶
Estimated time to read: 20 minutes
Strategic Proposals, SRE Operational Integration, Proactive Risk Management, Tooling Ecosystems, and Post-Incident Learning¶
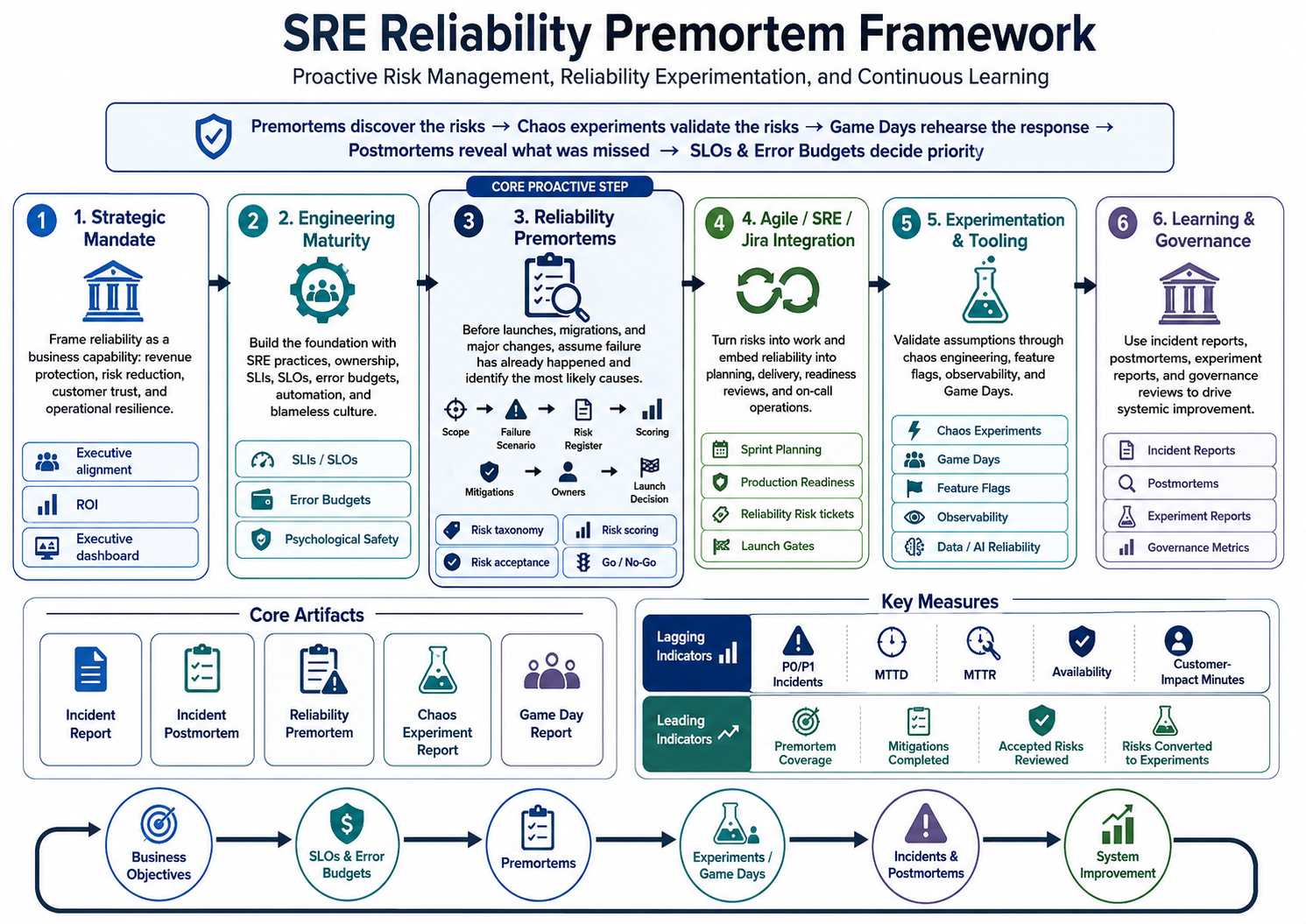
Modern software systems operate in distributed, cloud-native environments where failure is inevitable. Reliability can no longer depend on prevention alone. It must be designed, measured, rehearsed, tested, and continuously improved.
This framework defines how an organisation can move from reactive incident response to proactive reliability management. It combines Site Reliability Engineering, proactive project premortems, chaos engineering, observability, Agile delivery integration, risk governance, Game Days, and post-incident learning into one operating model.
The central principle is,
Premortems discover the risks. Chaos experiments validate the risks. Game Days rehearse the response. Postmortems reveal what was missed. SLOs and error budgets decide priority.
The framework is organised around six capabilities: executive alignment, engineering maturity, premortem-led risk discovery, SRE and Agile integration, experimentation tooling, and continuous learning.
Positioning Reliability as a Business Capability¶
A common barrier to reliability investment is the gap between engineering reality and executive perception. Engineers often see reliability experimentation as a technical necessity, while executives may view it as competing with feature delivery or growth initiatives. The reliability narrative must therefore be expressed in business terms: revenue protection, risk reduction, customer retention, regulatory confidence, engineering productivity, and reputational protection.
Reliability should be positioned as a strategic control that protects digital revenue streams and customer trust. Downtime does not only create immediate loss; it also creates support demand, executive escalation, contractual risk, roadmap disruption, and reputational damage. A reliability programme is therefore a form of business insurance: a controlled investment that reduces the frequency, severity, and duration of failure.
Executive Viewpoints¶
| Executive | Reliability Concern | How to Frame the Value |
|---|---|---|
| CEO | Growth, reputation, market confidence | Reliable services protect customer trust and competitive position. |
| CFO | Cost, ROI, margin protection | Reliability reduces outage cost, SLA penalties, rework, and wasted engineering time. |
| CTO / VP Engineering | Velocity, architecture, technical debt | Proactive reliability reduces firefighting and improves delivery predictability. |
| CISO / Risk Officer | Availability, continuity, compliance | Reliability strengthens operational resilience and disaster recovery readiness. |
Reliability ROI. Reliability ROI should be calculated by comparing the cost of the reliability programme with avoided losses and productivity gains. The baseline should include incident frequency, MTTR, MTTD, customer-impact minutes, lost revenue, support cost, SLA exposure, rollback frequency, and engineering time consumed by response or rework.
A simple model is:
The exact calculation should be adapted to the organisation, but the intent is consistent: show that reliability investment protects revenue, reduces waste, and improves execution.
Executive Dashboard. The executive dashboard should translate technical reliability into business impact.
| Metric | Executive Meaning |
|---|---|
| Availability | How often customers can successfully use the service. |
| Error budget burn | Whether reliability risk is being consumed too quickly. |
| MTTD and MTTR | How quickly the organisation detects and restores service. |
| P0/P1 incidents | Frequency of major operational disruption. |
| Customer-impact minutes | Total user-visible degradation. |
| Revenue at risk | Financial exposure from service degradation. |
| Open high-risk reliability items | Known unresolved operational risk. |
| Accepted reliability risks | Risks consciously carried by the business. |
| Premortem coverage | Percentage of high-risk launches reviewed before execution. |
| Experiment validation rate | Percentage of key risks tested through experiments or Game Days. |
Engineering Maturity and Cultural Readiness¶
Reliability depends on more than tooling. It requires trust, ownership, measurable objectives, disciplined execution, and a culture that treats failure as a source of learning.
Organisations often begin in a reactive state, where incidents depend on individual heroics, deployments are risky, monitoring is incomplete, and operational knowledge is concentrated in a few people. They then move toward structured delivery, where CI/CD, code review, release management, and incident processes improve consistency. The next stage is SRE-driven reliability, where operations are treated as an engineering discipline through automation, SLOs, error budgets, runbooks, and production readiness reviews. The most mature stage is proactive resilience management, where teams use premortems, historical incident analysis, dependency mapping, and controlled experiments to identify risks before customers experience them.
SLIs, SLOs, and Error Budgets. Service Level Indicators measure user-visible behaviour such as request success rate, checkout completion rate, latency, data freshness, or job completion rate. Service Level Objectives define the target level for those indicators, such as “99.9% of checkout requests complete successfully within 500ms over a rolling 30-day window.” Error budgets define the amount of unreliability allowed by an SLO.
This vocabulary gives product, engineering, SRE, and leadership a shared way to balance speed and stability. When an error budget is healthy, teams can move faster. When it burns too quickly, reliability work should take priority.
Psychological Safety and Blameless Learning. Premortems, chaos experiments, Game Days, and postmortems all require psychological safety. Engineers must be able to say that a migration plan has a rollback gap, a dependency is fragile, an alert is weak, or a launch deadline is creating operational risk.
Blamelessness does not remove accountability. It redirects accountability toward improving the system. The goal is not to ask who caused a failure, but what conditions allowed the failure to happen and how those conditions can be changed.
Proactive Risk Discovery Through Reliability Premortems¶
A reliability premortem is a structured, blameless exercise conducted before a major launch, migration, architectural change, production experiment, Game Day, or high-risk operational activity. Instead of waiting for an incident to reveal weaknesses, the team assumes the initiative has already failed and works backward to identify the most plausible causes.
The purpose is not to predict the future perfectly. The purpose is to expose hidden assumptions, reduce overconfidence, identify weak signals, and convert vague concerns into concrete reliability work.
Premortems should become a standard control for Tier 0 and Tier 1 services, high-risk launches, database migrations, critical dependency changes, disaster recovery changes, major platform upgrades, high-blast-radius experiments, and significant ownership transitions.
Premortem Workflow¶
| Step | Activity | Output |
|---|---|---|
| 1 | Define the project, change, or system under review. | Scope statement |
| 2 | Identify affected services, dependencies, and customer journeys. | Impact map |
| 3 | Review relevant SLIs, SLOs, error budgets, and incident history. | Reliability context |
| 4 | Assume the initiative failed badly and describe the failure. | Failure scenario |
| 5 | Collect possible causes individually before group debate. | Raw risk list |
| 6 | Group and score risks using a standard taxonomy. | Prioritised risk register |
| 7 | Define mitigations, experiments, owners, and due dates. | Action plan |
| 8 | Record residual risks requiring acceptance or escalation. | Risk acceptance record |
| 9 | Use the output to inform launch readiness. | Go/no-go recommendation |
| 10 | Revisit after launch, experiment, or incident. | Learning loop |
The facilitator should create space for independent thinking before discussion. Silent risk writing is important because it reduces groupthink and allows less senior participants to surface concerns.
SRE Premortem Risk Taxonomy¶
| Category | Questions to Ask |
|---|---|
| Availability and latency | What could make the service unreachable, slow, or degraded? |
| Capacity and scalability | What happens if demand is two, five, or ten times higher than expected? |
| Data integrity | What could corrupt, duplicate, lose, delay, or stale data? |
| Dependencies | Which internal or third-party dependencies can break the service? |
| Deployment and rollback | What could fail during rollout, migration, or rollback? |
| Observability and alerting | Would the right team know quickly and receive useful context? |
| Recovery and runbooks | Can the team restore service within RTO and RPO expectations? |
| Security and compliance | Could failure expose data, violate policy, or trigger regulatory risk? |
| Human and process risk | Are ownership, approvals, handoffs, and support paths clear? |
| Business impact | What revenue, SLA, contractual, customer, or reputational damage could occur? |
Risk Scoring. A simple and consistent scoring model is usually more useful than a complex one. Each material risk should be scored from 1 to 5 for severity, likelihood, detectability, and recoverability. A higher detectability score means the issue is harder to detect. A higher recoverability score means recovery is harder.
| Risk | Severity | Likelihood | Detectability | Recoverability | Score |
|---|---|---|---|---|---|
| Rollback process has not been tested | 5 | 3 | 4 | 4 | 240 |
| Payment dependency timeout causes checkout failures | 5 | 3 | 3 | 4 | 180 |
| Dashboard lacks business-impact metrics | 3 | 4 | 5 | 2 | 120 |
| Autoscaling lags during launch traffic spike | 4 | 4 | 2 | 3 | 96 |
Risk scoring should support prioritisation, not create false precision.
Premortem Report Template. A premortem should produce a durable artifact. The report should capture the project, date, facilitator, participants, service owner, SRE owner, product owner, affected services, customer journeys, business criticality, related SLOs, error budget status, target launch date, architecture references, and relevant incident history.
The core of the report should include five sections.
| Section | Purpose |
|---|---|
| Assumed failure scenario | Describes the imagined failure as if it has already happened. |
| Risk register | Records risks, categories, scores, owners, and mitigations. |
| Required mitigations | Lists actions that must be completed before launch. |
| Accepted risks | Captures residual risks, approvers, expiry dates, and guardrails. |
| Experiments and Game Days | Converts high-priority risks into validation or rehearsal activities. |
The launch recommendation should be explicit: proceed, proceed with mitigations, proceed with accepted residual risk, delay launch, require additional testing, require a Game Day, or escalate to leadership.
Ownership and Risk Acceptance. Premortems require clear ownership. The SRE lead usually facilitates the session and validates operational risk. The service owner owns service-specific mitigations. Product clarifies business impact and launch trade-offs. Engineering management ensures remediation work is prioritised. Security and risk representatives review compliance exposure. Support identifies customer-facing readiness gaps. Executives accept material residual business risk where required.
Not every risk can be remediated before launch. Some risks may be accepted because of business urgency, limited blast radius, low likelihood, or temporary controls. Accepted risk must still be explicit, time-bound, owned, monitored, and reviewed. It should never become invisible risk.
Go/No-Go Criteria. A launch should not proceed without explicit review if ownership is unclear, no SLO exists for a critical journey, rollback has not been tested, monitoring does not cover major failure modes, paging routes are unclear, runbooks are stale, high-severity risks lack mitigation or acceptance, error budget impact is unknown, dependency failure behaviour has not been tested, or customer support readiness is incomplete.
These criteria give the premortem practical authority rather than making it a discussion-only exercise.
Operational Integration with Agile, SRE, and Jira¶
Reliability practices fail when they remain separate from normal delivery. Premortems, chaos experiments, production readiness reviews, and incident follow-ups must become part of how teams plan and ship work.
In sprint planning, teams should review open premortem risks, SLO violations, error budget burn, incident actions, experiment findings, runbook gaps, and observability improvements. Reliability work should be estimated, prioritised, and assigned like product work. Many teams reserve 10–15% of sprint capacity for reliability, automation, technical debt reduction, and resilience validation, adjusting the allocation based on service criticality and error budget status.
Daily standups should surface reliability blockers where relevant. Sprint reviews should demonstrate reliability improvements alongside product features. Retrospectives should examine whether reliability risks disrupted planned work, whether alerts were actionable, whether runbooks were useful, and whether risks were discovered too late.
SRE Operating Cadence¶
| SRE Activity | Premortem Integration |
|---|---|
| Design review | Identify architectural failure modes before implementation. |
| Production readiness review | Validate ownership, observability, rollback, and recovery readiness. |
| SLO review | Check whether risks threaten user-facing reliability targets. |
| Error budget review | Identify risks that could rapidly consume reliability budget. |
| Launch readiness | Use premortem outcomes as go/no-go input. |
| Game Day planning | Select scenarios from high-scoring premortem risks. |
| Chaos experiment backlog | Convert plausible failures into testable hypotheses. |
| On-call readiness | Verify alerts, dashboards, escalation paths, and runbooks. |
| Incident postmortem review | Compare actual failures against predicted risks. |
| Quarterly reliability planning | Identify recurring risk themes across services. |
Jira Workflow. Reliability risks should be tracked as first-class work items. A dedicated issue type called “Reliability Risk” should include the service, customer journey, related SLO, error budget, category, score, owner, mitigation owner, target date, launch-blocker status, accepted-risk status, approver, review date, and links to related experiments, Game Days, incidents, runbooks, or dashboards.
The workflow should move risks through a lifecycle such as identified, scored, mitigation planned, in progress, mitigated, accepted, converted to experiment, waiting for launch review, closed, or reopened after incident.
Where possible, workflow updates should be automated. A failed resilience test can create or update a Jira risk. A breached SLO can open an investigation. A high-risk premortem item can block launch readiness approval. A completed mitigation can trigger a validation experiment.
Game Days and Fire Drills¶
Automated tests validate routine failure modes, but Game Days rehearse the human and technical response to major disruption. A Game Day should test detection, escalation, incident command, runbooks, dashboards, rollback, failover, customer support coordination, executive communication, and recovery speed.
Scenarios should come from high-scoring premortem risks, prior incidents, near misses, architecture reviews, disaster recovery requirements, customer-impact analysis, and SLO trends. Common examples include regional cloud outage, database failover failure, payment provider timeout, queue saturation, cache corruption, DNS misconfiguration, authentication outage, data pipeline failure, traffic spike, or rollback failure.
Game Day Structure¶
| Phase | Purpose |
|---|---|
| Scenario definition | Define the failure, affected services, customer impact, expected behaviour, and success criteria. |
| Recovery objectives | Set RTO, RPO, detection target, escalation target, mitigation target, and error budget threshold. |
| Safety planning | Define blast radius, abort conditions, kill switch, rollback plan, observers, and communication channels. |
| Execution | Inject the failure, observe system behaviour, track human response, and collect evidence. |
| Review | Document what worked, what failed, what needs improvement, and what follow-up actions are required. |
Abort conditions must be agreed before the exercise. The Game Day should stop if error budget burn exceeds the threshold, real customer impact exceeds the permitted blast radius, excluded systems are affected, failover fails unpredictably, or the incident commander declares continuation unsafe.
Reliability Tooling and Observability Ecosystem¶
A robust reliability framework requires tools that can inject faults safely, observe system response accurately, automate workflows, and preserve evidence for learning. Tooling should support controlled fault injection, blast-radius limits, abort conditions, service discovery, dependency mapping, observability integration, CI/CD integration, feature flag integration, RBAC, audit logging, experiment reporting, and workflow integration.
Fault Injection Tooling¶
| Tool / Platform | Classification | Core Strengths | Best Suited For |
|---|---|---|---|
| Gremlin | Commercial SaaS | Broad fault library, safety controls, reliability management workflows. | Large enterprises seeking managed chaos engineering. |
| Steadybit | Commercial | Visual experiment design, extension framework, reliability recommendations. | Teams needing customisable experiments across hybrid environments. |
| Harness Chaos Engineering | Commercial / Litmus-based | CI/CD integration, pipeline-native chaos testing, automated diagnostics. | Organisations already using Harness delivery pipelines. |
| AWS Fault Injection Simulator | Cloud-native | Native AWS integration, IAM controls, CloudWatch integration. | AWS-centric teams needing controlled infrastructure experiments. |
| LitmusChaos | Open Source / CNCF | Kubernetes-native CRDs, GitOps-friendly workflows, ChaosCenter. | SRE teams operating Kubernetes environments. |
| Chaos Mesh | Open Source / CNCF | Advanced Kubernetes network, resource, and pod-level disruption. | Teams needing fine-grained Kubernetes failure testing. |
Feature Flags as a Surgical Chaos Mechanism. Feature flags are useful for more than progressive delivery. They can also simulate failure in a precise and reversible way. A team can use flags to inject latency, force fallback logic, return simulated dependency errors, disable non-critical features, or expose only a small percentage of traffic to a degraded path.
This is valuable because it limits blast radius, allows targeted cohorts, supports instant rollback, and tests application-level resilience without always relying on infrastructure-level disruption.
Observability Requirements. Fault injection without observability is unsafe and low-value. Every experiment should be measurable through metrics, logs, traces, events, service maps, dependency graphs, synthetic monitoring, real-user monitoring, alert routing, error budget dashboards, and experiment annotations.
For every critical service, observability should answer whether the service is healthy, whether users are affected, which dependencies are degraded, which SLO is burning, what changed recently, who owns the failing component, what mitigation is available, and what rollback path exists.
Data, AI, and ML Reliability. Reliability extends beyond application uptime. A system can be technically available while still failing the business because data is stale, corrupted, delayed, duplicated, incomplete, or unsuitable for downstream models.
Data reliability should cover freshness, schema stability, completeness, accuracy, volume anomalies, duplicate records, late events, model input quality, and pipeline completion time. Data chaos experiments can delay pipelines, introduce malformed records, simulate upstream data loss, change schemas unexpectedly, or test warehouse unavailability.
Where AI or ML is involved, premortems should consider unavailable inference, stale features, distribution shift, low-confidence outputs, third-party AI dependency failure, fallback behaviour, unsafe outputs, and manual override paths.
Connecting Premortems to Chaos Experiments¶
Premortems are one of the strongest inputs into the chaos experiment backlog. They identify plausible failure modes before those failures occur. Chaos experiments then validate whether the system can withstand those failure modes.
A typical conversion flow is simple: the premortem identifies a risk, the team scores it, high-scoring risks become hypotheses, hypotheses become controlled experiments, experiments run with guardrails, and results become mitigations, accepted risks, or follow-up experiments.
Example Conversion¶
| Stage | Example |
|---|---|
| Premortem risk | If the payment provider slows down, checkout threads may exhaust the worker pool. |
| Hypothesis | If payment provider latency increases to 3 seconds, checkout should degrade gracefully. |
| Experiment | Inject 3-second latency into payment-provider calls for 5% of traffic. |
| Guardrails | Abort if checkout error rate or queue depth exceeds safe thresholds. |
| Success criteria | Circuit breaker opens, fallback activates, alert fires, and no worker exhaustion occurs. |
| Follow-up | Tune timeout thresholds and update the runbook if behaviour differs from expectation. |
Before running an experiment, the team should confirm that the hypothesis, steady state, target, blast radius, monitoring, alert routes, rollback, abort conditions, stakeholders, owner, and evidence capture are ready.
Reliability Metrics and Governance¶
Reliability governance requires both lagging and leading indicators. Lagging indicators show what has already happened. Leading indicators show whether the organisation is reducing risk before incidents happen.
| Metric Type | Examples | Purpose |
|---|---|---|
| Lagging indicators | P0/P1 count, MTTR, MTTD, customer-impact minutes, availability, SLA breaches, rollback frequency. | Measure reliability outcomes after impact has occurred. |
| Leading indicators | Premortem coverage, high-risk findings mitigated, accepted risks reviewed, risks converted to experiments, stale runbooks, alert quality. | Measure whether the organisation is reducing risk before impact. |
A recurring reliability governance forum should review SLO compliance, error budget status, open high-risk items, accepted risks, upcoming high-risk launches, premortem coverage, experiment outcomes, Game Day findings, unresolved postmortem actions, repeat incident patterns, and systemic investment needs.
Reliability Learning Artifacts¶
The reliability learning system depends on distinct but connected artifacts. They should not be merged into one generic template because each has a different purpose.
| Document Type | Purpose | Timing | Tone |
|---|---|---|---|
| Incident Report | Record what happened during an unplanned event. | During or immediately after incident. | Factual and chronological. |
| Incident Postmortem | Explain why the incident happened and how to prevent recurrence. | Within 24–72 hours after resolution. | Analytical and blameless. |
| Reliability Premortem | Identify plausible failure modes before a project or change. | Before launch, migration, experiment, or major change. | Proactive and risk-focused. |
| Chaos Experiment Report | Document the outcome of a controlled resilience test. | Immediately after experiment. | Scientific and empirical. |
| Game Day Report | Evaluate technical and human readiness under simulated failure. | Immediately after Game Day. | Operational and evidence-based. |
An Incident Report should capture the timeline, detection source, affected systems, customer impact, business impact, severity, responders, immediate actions, communications, resolution time, and current status. It should avoid blame, speculation, or premature root cause claims.
An Incident Postmortem should include the executive summary, impact, timeline, root cause analysis, contributing factors, what went well, what went poorly, detection gaps, response gaps, prevention gaps, action items, owners, deadlines, and links to related Jira issues, premortems, or experiments.
A Chaos Experiment Report should include the experiment date, environment, target service, steady-state baseline, hypothesis, fault injected, blast radius, guardrails, abort conditions, observed behaviour, SLO impact, error budget impact, detection performance, recovery performance, result, action items, and follow-up experiments.
A Game Day Report should include the scenario, participants, incident roles, timeline, detection performance, escalation performance, runbook effectiveness, dashboard effectiveness, communication effectiveness, customer support readiness, recovery actions, success criteria evaluation, gaps discovered, and follow-up actions.
After every significant incident, the postmortem should compare actual failure against prior premortems. The team should ask whether the failure was predicted, whether it was mitigated, whether it was accepted, whether the mitigation failed, whether follow-through failed, or whether the premortem taxonomy needs to be improved.
Unified Reliability Learning Cycle¶
The framework creates a continuous reliability flywheel. Business objectives define critical user journeys. Critical journeys define SLIs and SLOs. SLOs define error budgets and reliability priorities. Premortems identify plausible future failures. Risk scoring prioritizes action. High-priority risks become mitigations, accepted risks, launch blockers, experiments, or Game Day scenarios. Experiments validate assumptions. Game Days rehearse response. Incidents reveal unknown gaps. Postmortems convert failure into systemic improvement. Learning then feeds back into premortems, SLOs, tooling, runbooks, and architecture.
This cycle shifts the organisation from reactive recovery toward proactive resilience management.
Implementation Roadmap¶
| Phase | Objective | Core Deliverables |
|---|---|---|
| 1. Establish foundations | Identify critical services, owners, user journeys, SLIs, SLOs, and incident templates. | Service catalogue, ownership map, initial SLOs, incident and postmortem templates, reliability dashboard. |
| 2. Introduce premortems | Create the premortem process, risk taxonomy, scoring model, and risk register. | Premortem guide, report template, Jira issue type, accepted-risk process. |
| 3. Integrate with delivery | Connect risks to sprint planning, production readiness, SLO review, and launch gates. | Production readiness checklist, go/no-go criteria, SRE cadence, governance dashboard. |
| 4. Add experimentation | Convert top risks into experiments and Game Days with safety controls. | Experiment backlog, Game Day playbook, abort criteria, experiment reports. |
| 5. Automate and scale | Automate risk workflows, evidence capture, service ownership links, and trend reporting. | Automated Jira integration, reliability scorecards, cross-team governance model. |
Example, Payment Service Launch¶
A team is launching a new payment orchestration service responsible for checkout authorisation, provider routing, retry logic, and transaction status updates. The premortem assumes that four weeks after launch, the service caused intermittent checkout failures during peak traffic, retried provider calls too aggressively, exhausted worker pools, delayed transaction updates, and burned through the checkout error budget within 48 hours.
| Risk | Category | Score | Required Action |
|---|---|---|---|
| Rollback path is untested | Deployment risk | 240 | Run rollback rehearsal before launch. |
| Payment provider latency exhausts worker pool | Dependency failure | 180 | Run latency injection experiment. |
| Retry storm overloads internal queue | Capacity | 160 | Add retry budget and queue guardrail. |
| Dashboard lacks provider-level failure view | Observability | 120 | Add provider-specific dashboard. |
| Support team lacks customer messaging | Support readiness | 80 | Prepare support playbook. |
The highest-priority experiment tests whether the service degrades gracefully when the primary payment provider slows down. The experiment injects 3-second latency into payment-provider calls for a limited traffic cohort. Success requires the circuit breaker to open, eligible traffic to move to the secondary provider, queue depth to remain safe, the alert to fire within two minutes, and checkout errors to remain within the SLO threshold.
The launch should proceed only after the rollback rehearsal passes, retry guardrails are implemented, provider-level observability is available, the latency experiment passes, and the support playbook is approved.
Conclusion¶
A modern reliability framework must do more than react to incidents or run isolated chaos experiments. It must create a disciplined system for identifying, prioritizing, validating, and governing operational risk before customers are affected.
Premortems are the proactive layer that completes the SRE operating model. They allow SRE, engineering, product, security, support, and leadership to identify the most plausible ways a project or system could fail before it goes live. When connected to SLOs, error budgets, Jira workflows, chaos experiments, Game Days, and postmortems, premortems become a practical reliability control rather than a theoretical planning exercise.
The result is a reliability model where executives fund reliability because it protects business outcomes, teams define reliability through measurable objectives, premortems expose likely future failures, Jira workflows enforce ownership, experiments validate assumptions, Game Days rehearse response, incidents reveal unknown gaps, and governance keeps risk visible until it is resolved or consciously accepted.
By adopting this framework, an organisation replaces hope with evidence, reactive firefighting with proactive risk management, and isolated reliability practices with a coherent SRE operating system.